정보 단위
컴퓨터는 0 또는 1밖에 이해하지 못하는데, 0과 1을 나타내는 가장 작은 정보 단위를 비트(bit)라고 한다.
n비트는 2의 n승가지 정보를 표현할 수 있다.
바이트(byte)는 여덟 개의 비트를 묶은 단위로, 비트보다 한 단계 큰 단위이다.
| 1바이트 | 8비트 |
| 1킬로바이트 | 1,000바이트 |
| 1메가바이트 | 1,000킬로바이트 |
| 1기가바이트 | 1,000메가바이트 |
| 1테라바이트 | 1,000기가비이트 |
워드(word) : CPU가 한 번에 처리할 수 있는 데이터 크기를 의미. CPU가 한 번에 16비트를 처리할 수 있다면 1워드는 16비트고, 32비트를 처리한다면 1워드는 32비트가 된다.
이진법
같은 숫자가 1을 넘어가는 시점에 자리 올림을 하여 0과 1, 두개의 숫자만으로 모든 수를 표현한다.
이진수의 음수표현
2의 보수를 통해 음수를 간주하는 방법이다. 2의 보수의 사전적 의미는 '어떤 수를 그보다 큰 2의n승에서 뺀 값'을 의미한다.
11(2)보다 큰 100(2)를 빼면 01이되고, 이 값이 음수로 표현된 값이 된다.
또는 모든 이진수의 0과 1을 뒤집고 +1을 해주면 된다. +1을 해주지 않으면 1의보수가 되고, 더한 값은 2의보수가 된다.
문자집합과 인코딩
컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 문자집합이라고 한다.
하지만 문자를 그대로 읽을 수 없기 때문에 문자를 0과 1로 변환하는 변환 과정을 문자 인코딩(character encoding)이라고 한다.
반대로, 0과 1을 문자로 변환하는 작업을 문자 디코딩(character decoding)이라고 한다.
아스키코드
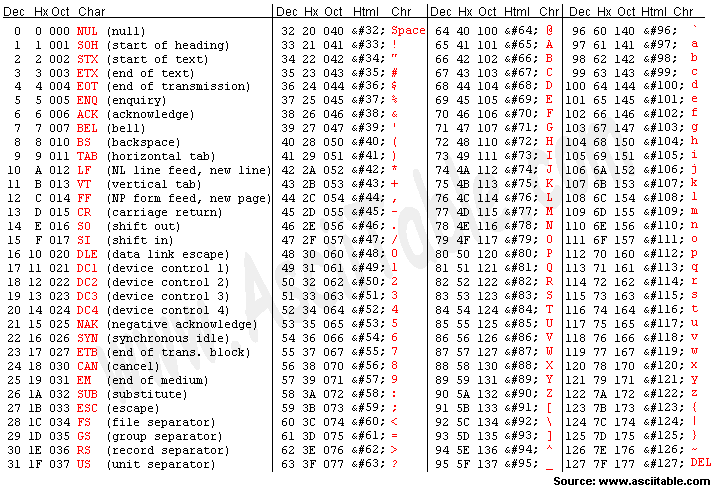
아스키(ASCII)는 초기 초창기 문자 집합 중 하나로, 총 128개의 문자를 표현할 수 있다. 하지만 아스키 코드로는 한글을 표현 할 수 없다.
한글 인코딩 방식이 바로 EUC-KR이다.
EUC-KR
한글은 각 음절 하나하나가 초성, 중성, 조엇ㅇ의 조합으로 이루어져 있다. 한글 인코딩에는 두 가지 방식이 존재한다. EUC-KR은 KS X 1001, KS X 1003이라는 문자 집합을 기반으로 하는 대표적인 완성형 인코딩 방식이다. 즉, 한글 단어에 2바이트 크기의 코드를 부여한다.
인코딩 방식으로 총 2,350개의 한글 단어를 표현할 수 있지만, 정의되지 않은 '벩', '쀓', '믜' 등과 같은 글자는 EUC-KR로 표현할 수 없다. 그래서 이를 통해 사용하면 웹사이트에서 한글이 깨지는 현상이 존재하기도 한다.
- 완성형(한글 완성형 인코딩)
- 방식은 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식이다. 예를 들어 '가'는 1, '나'는 2 이런 식으로 인코딩된다.
- 조합형(한글 조합형 인코딩)
- 반대로, 초성, 중성, 종성을 위한 비트열이 각각 나뉘어져 있어서, 비트열을 할당해 조합으로 하나의 글자 코드를 완성시킨다.
유니코드와 UTF-8
유니코드는 EUC-KR보다 훨씬 다양한 한글을 포함하며 대부분 나라의 문자, 특수문자, 화살표나 이모콘까지도 코드로 표현할 수 있는 통일된 문자 집합이다.
유니코드는 글자에 부여된 값 자체를 인코딩 값으로 삼지 않고 이 값을 다양한 방법으로 인코딩 한다. 방법으로는 UTF-8, UTF-16, UTF-32 등이 있다.
UTF-8
통상 1바이트부터 4바이트까지의 인코딩 결과를 만들어 낸다. 인코딩한 값의 결과는 1바이트가 될 수도, 2, 3, 4바이트가 될 수도 있다.
'혼자 공부하는 컴퓨터구조 + 운영체제' 카테고리의 다른 글
| 명령어 사이클과 인터럽트 (0) | 2022.10.05 |
|---|---|
| CPU 작동원리 (0) | 2022.10.05 |
| 연산코드와 오퍼랜드 (0) | 2022.09.29 |
| 소스코드와 명령어 (0) | 2022.09.27 |
| 컴퓨터 구조와 운영체제 왜 공부해야할까? (0) | 2022.09.24 |